Apache Druid is A Scalable Timeseries OLAP Database System. OLAP systems are heart of Business Intelligence, multi dimensional Analytical query and Data Science applications. Druid, as of this writing, can be deployed to Azure as an IaaS service and the PaaS offering still not out. Neither Druid has options to deploy as Marketplace Product. The assumption for the below architecture is Druid is deployed in OnPremise Kubernetes infrastructure with Pure storage(PureBlock and PureFile) backbone and transformations is offered with change in Storage tiers and technologies native to Azure world
Azure Data Storage Architecture for Druid
Below diagram specifies how the Azure Storage can be distributed across multiple storage tiers for Druid Database related to different Key components for Druid Datastore:
Azure Managed Disk – Historical Nodes needs Low latency and High throughout Disk IO storage for Fast mapping to memory address space . This could be Standard SSD or Premium Ultra Fast SSD tier for optimized performance.Each Historical POD need access to dedicated Managed disk dynamic provisioned mount
Azure File Storage – Middle manager nodes need fast Batch data access from NFS like file share which is typically offered by Azure Native File storage with NFS or SMB protocols. Since Multiple Middle Manager PODS needs access to a common storage hence Azure file storage is easy supplement
Azure Gen2 Blob Data Lake Storage – Druid Deep storage needs fast but cheap storage options alternative to S3 or HDFS supplemented by ADLS Gen2
Azure MySQL or PostgreSQL – Druid Metadata config store could be either MySQL or PostgreSQL . If HA is needed then PostgreSQL Patroni could be preferred choice.
Distribution of Druid POD’s and Storage provisioned Between Azure Managed and File Storage
Druid Deep Storage needs to be provisioned from Azure Gen2 Blob Storage similar as S3 in AWS . The configuration how to include the Deep Storage Azure needs be using Azure Druid Extensions
Druid needs below property to be set before mounting Deep Storage in ADLS :
Property
Description
Possible Values
Default
druid.storage.type
azure
Must be set.
druid.azure.account
Azure Storage account name.
Must be set.
druid.azure.key
Azure Storage account key.
Must be set.
druid.azure.container
Azure Storage container name.
Must be set.
druid.azure.prefix
A prefix string that will be prepended to the blob names for the segments published to Azure deep storage
“”
druid.azure.protocol
the protocol to use
http or https
https
druid.azure.maxTries
Number of tries before canceling an Azure operation.
3
druid.azure.maxListingLength
maximum number of input files matching a given prefix to retrieve at a time
1024
Storage account and Containers for Druid in Azure
Imply has Deployment steps in AKS and Config for Azure Storage account mentioned here
Storage Provisioned for Druid Data servers (Middle Manager and Historical)
Create StorageClass (Azure Managed Premium Disk)
Create Persistent Volume Claim
Create Pods using the PV and mount the PV inside a dedicated Mount store ‘
This created nginx POD up and running and Bound to PVC with ReadWriteOnce mode (Note Azure Disk storagecClass can’t be ReadWriteMany) and it is mounted Storage inside /mnt/Azure.
Inside POD how this will looks like : Note 1 GB mount requested is provisioned under /dev/sdc
“There are only two hard things in Computer Science: cache invalidation and naming things.”
Phil Karlton
Preamble:
As enterprises start to utilize Azure resources, even a reasonably small footprint can begin to accumulate thousands of individual resources. This means that the resource count for much larger enterprises could quickly grow to hundreds of thousands of resources.
Establishing a naming convention during the early stages of establishing Azure architecture for your enterprise is vital for automation, maintenance, and operational efficiency. For most enterprises, these aspects involve both humans and machines, and hence the naming should cater to both of them.
Objective – Naming standards saves any teams countless number of hours to think , making mistakes and carry with those mistakes and suffer others and be religious in cloud eco system. This thread will outline what are the technical guardrails we can adopt inside naming to instrument this as practice. Idea is to follow KISS principle – “Keep it simple, stupid” .
Naming conventions always end up with heated debates and someone could be very arrogant to propose “one-size-fits-all” kind of theory but chill ! Lets first understand what can we do best for our own benefit.
WHY TO ADOPT BEST PRACTICE/ RECOMMENDATIONS
Synchronous / Rhythmic and Orderly / Pleasant to seeDo what you want / Go All over the places ?
What is Azure Resources
Any component got to do some work is resource in Azure World. Here is simple resource structure in Azure
Management groups: These groups are containers that help you manage access, policy, and compliance for multiple subscriptions. All subscriptions in a management group automatically inherit the conditions applied to the management group.
Subscriptions: A subscription logically associates user accounts and the resources that were created by those user accounts. Each subscription has limits or quotas on the amount of resources you can create and use. Organizations can use subscriptions to manage costs and the resources that are created by users, teams, or projects.
Resource groups: A resource group is a logical container into which Azure resources like web apps, databases, and storage accounts are deployed and managed.
Resources: Resources are instances of services that you create, like virtual machines, storage, or SQL databases.
When Naming resources in cloud, degree of governance and guidelines is very important to drive a successful tidy thoughtful environment.
Hence tagging and naming is BOTH important factors for developers/administrator/config manager to follow.
What important factors driving naming standards ?
Consistency – Makes DevOps engineers job easy
Remove Redundancy
Scalability and Flexibility
Avoid Confusion
Ease of Management – Easy to follow and easy to identify resources/pin point product and application owners in few seconds
Billing/Charge Back – Easy to find the resource usage cost by tagging and naming
Better monitoring and logging
Habit the practice – you will live with this names and spend lot of time with them so make them pleasure to work with
Renaming Resources – Azure resource and resource group can’t be renamed once created. Renaming is moving all your resources from one group to other and it potentially impact lot of places
What is excluded ?
Below will not follow the naming conventions as those are automated by Azure itself.
Naming for the Resources auto-generated by Azure like Managed Disk name (e.g. <VMName>_OsDisk_1_25fbb34c5b074882bcd1179ee8b87eeb)
Supporting resource group for Azure Kubernetes Service
Some resources require a globally unique name
Internal Resource group name related to Databricks for e.g. – databricks-rg-dev000hidpuse02dbricks001-44gxjl4c7ailk
Azure Regions for Deployment of Resource Group and Resources
EAST US2 is 10% cheaper from EAST US and have better resource availability
Co-locating resources at same location will help reducing ingress and egress cost of data transfer for any integration work
Key Resource Group(KRG) Naming
Resource group prefix – e.g. – rg (short stands for resource group) (this will simplify the search while creating any resources)
Department / Business Unit Name – e.g. – hosbi , crs – preceding BU Name will help us to identify the sub from the merged corporate subscription tree
Type of the resources under that resource groups. e.g. for db, app, devops, ml, k8s
Environment Type – e.g. – dev, prd
Regional Instance Identifier ( azure datacenter) – e.g. eastus, westus – Not mandatory to be explicitly mentioned and maintained specially when business agreed all resources to use specific region
Incrementor: 01, 02, 03 etc if required (can be used for redundant copy of existing resource group or brand new resource group to be used by different team under same business unit ) .
Role/Function of resources/Primary Use – e.g. operation, config, cache, analytics, oltpds, olapds, db, web, mail, shared (when this resource will be shared across resource groups)
Regional Instance Identifier( azure datacenter) -e.g. eastus, westus – Not mandatory to be explicitly mentioned and maintained specially when business agreed all resources to use specific region
Incrementor: 01, 02, 03 etc if required – e.g. can be used for HA resources like Cluster nodes, VM scale sets.
For e.g. – dev-databricks-olap, prd-aks-analytics-eastus, dev-redis-cache, prd-postgres-oltp-config
Note: BU Name / Product Name subject to change with organizational merge hence better to keep those name for each KRI inside Tags and not in the naming itself.
Micro Service Container Naming convention
this can follow the standard POD naming when deploying the resource using the corresponding helm charts. Certain naming in POD can’t be controlled because it is managed inside kubernetes own realm
Naming standard challenges:
There are lot of naming rules across azure services. Some resource offers naming in hyphen or period characters where some are not. Some likes underscore while other prohibits any naming except alphanumeric characters.
Some allows naming to be certain number of characters some can have pretty lengthy naming and some allows uppercase where some are strictly lowercase
Unifying the Naming Construct and Separators
Usages
Description of Rules
CASE
Use lowercase always. camelCase, PascalCase, Initcap is not allowed.
WHITESPACE
no space allowed across any name
ABBREVIATION to shorten characters
where Resource name length > 8 characters use conformed and consistent abbreviated form like df for datafactory .
HYPHEN or DASH as Separator to break them up
If hyphen or Dash not allowed use Underscore(“_”) to supplement. If no special characters allowed in between use 1 as separator for e.g. poc1storage1db, poc1storage1olapds, poc1storage1shared . Rare case, as an example Storage name which doesn’t accept hyphen/dash neither any special characters. But Fileservice/blob services/containers underneath it can be names with hyphenUse hyphen(“-“) on resource name or resource group name as separator between resource identifier values for e.g. – prd-react-analytics-eastusDo not use more then 1 hyphen (“–”) as separator for e.g. dev–aks–olapds . Don’t use hyphen characters inside the name of resources itself for e.g. eventhubs should never be called as event-hubs rather use continuous naming or abbreviation if long name
START AND END Character
Never start any resources with hyphen(“-“) or any charactersNever end any resource name with hyphen(“-“) or any characters (like period(“.”) )Never start with Numeric value but end with numeric value is allowed, for e.g. – dev-couchbase-config-eastus2
INCREMENTOR
Use only when this make sense for e.g. Clusters, Multiple Nodes deployed for similar resources, VM Scale sets etcDon’t use 00 if no incrementor presentUse 0 padding – Never use 1/2/3 rather use 01/02/03
ENVIRONMENT Name
Shouldn’t be exactly 3 characters (dev, tst, stg, prd, prf, uat, poc) – qa should be analogous to tst or stg environment
CHARACTERS Limit
If KRI strings length is long enough to fit the allowable limit use additional tag to identify the resources. Some cases abbreviation can be used
REDUNDANT NAMING Cross Region
Avoid creating unnecessary number of resources for redundancy and HA because some services having built-in high availability(fault domains and update domains) and no need to create in different regions.
RESOURCE functions
This is very important to identify what is the purpose the resources and long term it will benefit identifying the purpose
Important Limitations
Scope:
Resources:
Constraint:
Alpha-Numeric
Storage Account Name
Cannot have dash, dot
Azure Cloud
SQL Server Name, Storage Account Name
Must be unique across Azure not just subscription
Length
Search Service and Virtual Machines
2 to 15 characters
Lower Case
Storage Account Name
Cannot be upper characters
Sample abbreviated naming for some Azure Resources
Resource/Service:
Short Code:
Long Code:
Subscription
sub
sub
Resource Group
rg
rg
Virtual Machine
vm
vm
Availability Set
avs
avset
Virtual Network
vn
vnet
Subnet
sub
subnet
Public IP Address
pip
publicip
Network Security Group
nsg
Networksg
Storage Account
stg
storage
TrafficManager
tm
trafficmgmr
Load Balancer
lb
loadbalancer
Application Gateway
agw
appgateway
App Service
svc
appsvc
Key Vault
kv
kv
App Service Plan
asp
appplan
Sql Database
sdb
sqldatabase
Sql Server
sql
sqlserver
Disk
dsk
disk
DNS Zone
dns
dnszone
Log Analytics
loa
loganalytics
Logic App
log
logapp
Network Interface
nif
netinterface
Tagging : Very useful to find the resource usage in Azure by Tag Name. Also it helps to categorize the similar resources under one Application or Product.
Another great use of tagging is Billing . It is great way to report the Cost Analysis. Note tagging is Key Value and Can be changed anytime but KRG / KRI is not simple rename.
There would be multi level tagging options:
Subscription
Resource Group
Resource
Tag name/value length: 512 / 256
Tag Name rule:
Name is the key , it can’t be duplicate string
Never use sequence like 1,2,3 in the name key for tag
Tagging Naming Conventions for Resource group (All parameters below are mandatory)
A common and good use of tags name and value combinations would be below:
Name
Sample Value
Allowed Values
Enforced by policy
Description (why needed ? )
business-unit
hosbi
should be only one value
Yes
if multiple product use hyphen(“-“) separator
owner
debashis-paul
use full name
identify who owns what, if middle name then add another hyphen(-)
Since Tag Name/Value at Resource Group level doesn’t recursively applied to Resource Name so we still need to apply Tagging pair at individual resource level.
Tagging Naming Conventions for Resource Name (All parameters below are mandatory)
Name
Sample Value
Description (why needed ? )
business-unit
hosbi
if multiple product use hyphen(“-“) separator
owner
debashis-paul
identify who owns what, if middle name then add another hyphen(-)
Used for what platform poc, dev, test, production ?
thirdparty-sw
yes/no/all
e.g. couchbase, mongo, kafka, splunk, oracle which is marketplace product and non managed resources
billingowner
hosbi-<companyname>
Easy to filter and report cost sheet
Scripts to create resources and scripts to enforce such policies… Bookmark them. Non Prod or Prod subscription can’t create resource name/ groups without Script
Enforcing the naming and tagging practice:
ARM template scripts should be executed via Azure CLI / Powershell or Azure API while creating resources / tags following above rules for Prod and Non Prod env except POC environment
POC Subscription resource group should be easy to create without Scripts but should adhere above naming principles
NOTE
Resources with a public endpoint already have an FQDN which accurately describes what they are so some cases resource name is self explanatory while looking at default public endpoint URL azure creates:
Its a modern Lake House Architecture a blend of Data Lake and Warehouse
Ideal for structured data management solutions and not for complex variation of open source data types, it has closed proprietary formats, Its purpose-built
Collect large amount of many structured or unstructured data sources of variety of formats , Data semantics and Abstraction is not provided
Collect literally any data at any scale , Process any data at any scale andcreate outbound data at any scale
Support business intelligence with structured data support
Issue with usability and have severe limitations , Poor DW and BI support, Unreliable Data swamps
Any DW or DL limitations has been taken care of , usability is achievedvia optimized Delta lake by adding a transaction layer on top of data lake
High storage and processing cost for data at-least comparing sources like Data Lake
Suitable for storing Bulk volume of data at low cost, Complex setup
brings best of datalake and datawarehouse together A lakehouse is a scalable, low-cost option that unifies data, analytics and AI.
Supports performance with set of optimization processes , degree of data quality could be enforced , versioning need to be customized / maintained
Lack some critical reliability and performance features like transactions, data quality enforcement and consistency/isolation
Enable critical capabilities like ACID transactions, schema enforcement/evolutionand data versioning that provide reliability, performance and security to your data lake
Seamless unification of Batch and Streaming workload is hard of achieve , limited streaming capabilities
Difficult to handle and dealing with enormous number of files . Not easy to deal with files unless there is clear semantics
Delta Lake provides a unified framework for batch and streaming workloads on one simplified architecture that not only avoids complex , redundant system and operational challenges but also improving efficiency on data transformation pipelines, downstream activities like BI, data science and ML
Auto data versioning is not possible , No Direct support for Data Science and ML
Data versioning is not applicable as it is just ingest source
Delta Lake provides the ability to version your data sets, which is a really important feature when it comes to reproducibility.The ability to essentially pin your models to a specific version of your dataset is extremely valuable because it allows other members of your data team to step in and reproduce your model training to make sure they get the exact same results
Vendor Locking
Its open Object Store
No Vendor Locking base on Open source Data Lake and Spark
No in-built GDPR , CCPA compliance
NA
GDPR and CCPA data compliances leveraged by managed table in Delta Lake
Doesn’t provide wide verities of access modules for ACL’s and nothing comes OOB
NA
Delta Lake on Databricks, you can use access control lists (ACLs) to configure permission to access workspace objects (folders, notebooks, experiments and models), clusters, pools, jobs, and data schemas, tables, views, etc
Distributed and Decoupled Resource groups & Storage Account paradigm
Literally all resources in Azure needs underlying Storage to operate that starts from VM/Compute to Database to API/ Middleware/ Logs etc.
It is key to segregate the Storage accounts based on target workloads and there are primary four reasons, with other auxiliary reasons, how can this distribution benefitting us:
Security – It is important to apply policy and security governance across various resources that includes Storage accounts . this gives better control of the underlying Data and target audience who will work with that data Developers vs Tester and have tighter security control across Storage units/ Containers etc.
Performance – Its heart for a healthy application . Isolating the workloads based on needs could be key to achieve great performance without impacting one vs another
Ease of Management – Based on different AD group level permissions and advanced roles and management distributed Storage account paradigm gives added level and gears to better controlled by Administrator and better policy and security enforcement can be applied.
Cost analysis – When resources are in hierarchies its easy to get the cost sheet in much detail
The below diagram is high level vision how storage account could be distributed based on different Technology stacks and Teams for a Business Unit . This could be further integrated with other Business Unit for a complete enterprise solution
Azure Storage account Distributed Architecture
Idea for the above distribution is to isolate the Storage account for individual resource groups . In this example, for a business unit Database resources could be co-located under a unified resource group while Devops ML , Kubernetes native workload can have there own resource group . With resource group isolation we are isolating the associated storage accounts as well and those storage account layered into multiple logical units .
At the middle(in Orange) we have the special resource group where underlying storage account is shared across multiple technology areas for the specific business unit. A typical use case is this could be file landing areas which will be shared by Machine learning workload, batch or streaming workload and act as shared resources .
Difference between Azure Storage / File protocols and usages
Azure has multiple options for Storage services like BLOB , Gen2 ADLS, Managed Disk , File Storage and many services use very specific access protocols to facilitate the usages for specific needs .
I have outlined those services and protocols differences in many ways in below diagrams:
ADLS GEN2 and UsagesAKS Service and multiple storage provisioner usage in AzureUsing Azure File StorageADLS Gen2 Storage Account Access and UsagesAzure Netapp Files Usages
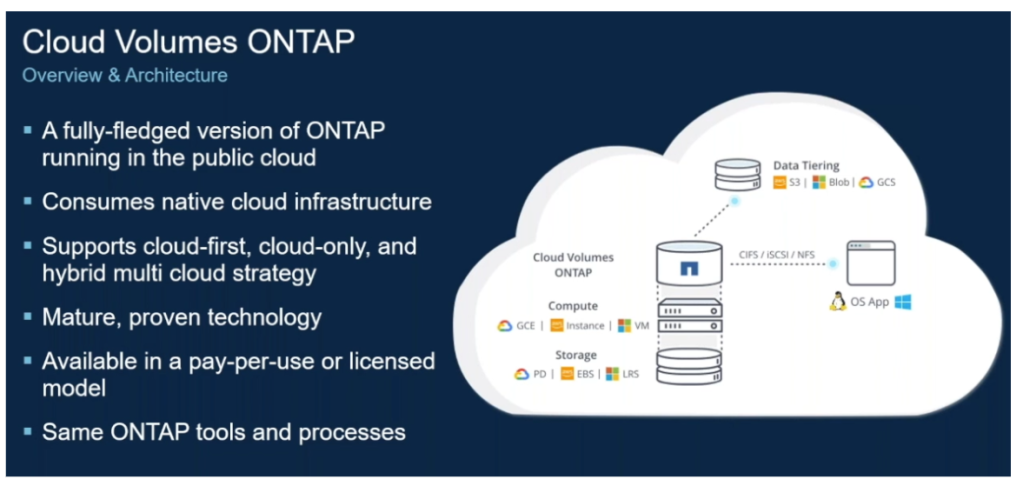
Netapp Volume in Cloud is exciting and specially the Netapp ONTAP product. ONTAP is abbreviated form of Open Network Technology for Appliance Products
ONTAP is separate license in Netapp Storage options in public Cloud offerings and it uses separate Storage appliances in Cloud.
ONTAP is great for providing the low latency high throughput IO operations at scale and speed for Block storages typically used for high volume of data transactions in milliseconds response. ONTAP has other exciting offerings of Data Tiering and simplifying the entire cloud data management at single glass on pane. Below is some key data captured for ONTAP in Cloud
Simplify storage management by easy setup using Azure Portal , CLI, Powershell, REST API
Multi protocol support (NFS/ SMB/ CIFS/ iSCSI)
Three performance tiers – Standard, premium and ultra and change on the fly with simple click
Data encryption at rest, RBAC, AD auth and network based ACL’s available
HIPPA and GDPR complaint with default 99.99% availability
Easy management of storage
ONTAP featured with thin/dynamic provisioning, data compresssion, de-duplication, compression, data tiering, flexible cloning, snapshot copies, ease of management via GUI or RESTful API and reduce cost footprint
ONTAP manages Netapp Block storage volume where multi instance read/write (typical for K8s statefulset workload) , Cloning , Data Protection, Data replications across AZ and Disaster recovery across Azure regions for HA
ONTAP supports iSCSI protocols for Block Storage and NFS/SMB for File
Non disruptive(zero performance penalty for running applications) Instantaneous point-in-time Snapshots , Applications and Database Integrated
Cross site snapMirror Data replication for backup / DR/ restore/ cloning and archive
Data tiering to move Hot Block Storage data to Object store and back and forth to save cost
Support Hybird Cloud Data movement and easy management by Netapp Cloud Manager
multi-AZ,dual-node,HA solution, designed for zero data loss (RPO = 0) and under 60-second recovery
Lets see some Demo how the ONTAP options works assuming you have already ONTAP product option picked from Azure Offerings page in Marketplace Product section.
20 Minutes HA Cluster for DeploymentAPI DrivenCross region deploymentMulti Protocol ProvisioningAdding new volumeChoosing Data tiering / retentioniqn copy from Windows VMAdding volume for the iSCSI map to Host and mapping and make it availableInitialization of DiskReplication SetupTarget Volume for ReplicationChoose replication policyVolume replicationPrimary to DR site replicationReplication features
Vendor agnostic open protocol to share the data real-time which simplifies cross organization data sharing securely and give access to that data to be analyzed by array of tools typically BI tools .
Below excerpt from the SparkAISummit of 2021 and hopefully this will help summarizes the current capabilities of Delta Share
DELTA SHARING DEMO
Sharing the Data to receipient
Data Sharing
For Data analyst to connect via Pandas Data Frame
For Analyst to Connect Delta Share via BI Tools like Tableau
Really ! probing Perl “the Legacy” to see how compatible with Modern “5th generation” Data Platform ! I guess this is terrible subject to pick . Yes, this thread is intended to criticize Perl programming and discourage using it. Perl is unique ,exotic but not attracts developers community as mainstream languages for past couple of years. The demise is not sudden but gradually painful for Perl community .
The objective of this thread is to prove how can you use Perl to connect with modern Delta Lakehouse platform Databricks not a simpler ways but with all kinds of highly discouraging bells and whistles. This is a assessment with facts and lets dive through that:
Perl usability in Azure
To use Perl in Azure it can be done :
using Perl Azure SDK – Not recommended as not supported yet by Microsoft – Its Alpha quality code by Open Source Community not stable yet and hence not available to CPAN (Comprehensive Perl Active Network) community . 2 Year old last commit in Github.
via Azure REST API – Recommended Approach which provides service endpoints that support sets of HTTP operations (methods) allow create, retrieve, update, or delete access to the service’s resources Azure REST API Index
There is no native or direct out of box connectivity exist unlike Perl DBI modules which is connected to Data sources like MySQL or Oracle directly
The connection must needs to happen via External JDBC or ODBC connector to Databricks Spark framework
Unlike Python , R , Java, Scala which is directly supported by Databricks Notebook Perl is not supported and there is no plan either to add that support
Perl can still be used to create Databricks resources in Azure and manage it via Azure API but to interact with resources (Clusters , Jobs , Notebooks) in Databricks workspace required Databricks REST API
Those drivers are compiled together with the C client libraries of the respective database engines. In case of SQLite, of course all the database engine gets embedded in the perl application.
As an example for Oracle connectivity
Connecting Databricks from Perl (Using JDBC)
Azure VM Connecting Spark Thrift Server of Databricks Module via Simba JDBC driver
Thrift JDBC/ODBC Server (aka Spark Thrift Server or STS) is Spark SQL’s part of Apache Hive’s HiveServer2 that allows JDBC/ODBC clients to execute SQL queries over JDBC and ODBC protocols on Apache Spark.
Spark ThriftServer convert ODBC/JDBC calls into a format that can be distributed to and processed by highly-parallel engine like Spark in an efficient manner.
With Spark Thrift Server, business users can work with their Shiny Business Intelligence (BI) tools, e.g. Tableau or Microsoft Excel, and connect to Apache Spark using the JDBC/ODBC interface. That brings the in-memory distributed capabilities of Spark SQL’s query engine (with all the Catalyst query optimizations) to environments that were initially “disconnected”.
STEPS
PREREQUISITE
A Virtual Machine in Azure (either Windows or Linux) – In this case I am using Ubuntu 18.04 bionic image
Perl 5.8.6 or higher
DBI 1.48 or higher
Convert::BER 1.31
DBD::JDBC module
Java Virtual Machine compatible with JDK 1.4 or Above
A JDBC driver – Simba JDBC Driver as Databricks recommended and supported
log4j 1.2.13 extension
Install Perl and associated Dependencies in VM
There are many ways to install Perl but best to use PERLBREW . Execute all this after SSH to the VM in Cloud.
$vi /home/dxpadmin/DBD-JDBC-0.71/log4j.properties log4j.logger.com.vizdom.dbd.jdbc = ALL
Correction of DBD module and Makefile :
edit 03_hsqldb.t file inside extracted DBD Archive directory : /home/dxpadmin/DBD-JDBC-0.71/t and search for ‘exit 1’ at end of file and comment it out and Save then do below:
$perl Makefile.PL $make $make test
Note: for different version of Perl or different OS package you might need gmake or dmake whichever compatible
It will be Accepting inbound connection as below :
Spin up Databricks Cluster and Configure the Auth Token In Databricks Assume that Databricks workspace and Cluster already set in place, Start the Cluster and copy the JDBC/ODBC option Note : for above its not important to have Credential passthrough disabled. Enabling it will make no difference the authentication mechanism works with auth personal token.
Now Click on User Settings and Generate a Token and keep that token handy to use in Connectivity code:
#!/home/dxpadmin/perl5/perlbrew/perls/perl-5.32.1/bin/perl
# Its FAKE user password token and Fake HOST/URL so please don't try to make FAKE attempt to access it !
use strict;
use DBI;
my $user = "token";
my $pass = "dapidbf97bbmyFAKEpassautha564de4d68055";
my $host = "adb-85321FAKE86014.14.azuredatabricks.net";
my $port = 9001;
my $url = "jdbc:spark://adb-853217FAKE2886014.14.azuredatabricks.net:443/default%3btransportMode%3dhttp%3bssl%3d1%3bhttpPath%3dsql/protocolv1/o/85321FAKE86014/1005-FAKE-okra138%3bAuthMech%3d3%3b"; # Get this URL from JDBC string of Databricks cluster. the URL encoding is VERY Important else it leads to failure connection with weird errors
### my $url = "jdbc:spark://adb-853217FAKE2886014.14.azuredatabricks.net:443/default;transportMode=http;ssl=1;httpPath=sql/protocolv1/o/85321FAKE86014/1005-FAKE-okra138;AuthMech=3"; # (Not use this as IT WILL GENERATE Authentication ERROR with SSL / Certificates)
my %properties = ('user' => $user,
'password' => $pass,
'host.name' => $host,
'host.port' => $port);
my $dsn = "dbi:JDBC:hostname=localhost;port=$port;url=$url";
my $dbh = DBI->connect($dsn, undef, undef,
{ PrintError => 0, RaiseError => 1, jdbc_properties => \%properties })
or die "Failed to connect: ($DBI::err) $DBI::errstr\n";
my $sql = qq/select * from products/;
my $sth = $dbh->prepare($sql);
$sth->execute();
my @row;
while (@row = $sth->fetchrow_array) {
print join(", ", @row), "\n";
}
In above example I am running simple select from Products table in Default Schema in Databricks Workspace . Lets look at the table data:
Now lets execute Perl Script :
This is what the JDBC Proxy server Logged : Ignore the LOG message as per Simba Documents
For Windows Azure VM requires setting up Strawberry Perl , Download DBD::JDBC module and copy the content for extracted DBD:JDBC to inside Strawberry directory : C:\Strawberry\perl\vendor\lib\DBD
It doesn’t need to run Makefile.PL and it should be ready to initiate JDBC proxy server to accept connections.
This is how it will look like in Azure Windows VM
Another easy way to test connectivity in Windows VM is to download Workbench and execute : C:\Workbench-Build125\Workbench-Build125\sqlworkbench.jar (Double click it) Manage Driver to add Simba 4.0 or 4.1 or 4.2 JDBC for Spark :
Now Pick the Spark Driver and Add JDBC connection string (as provided by Databricks) to see successful connection : (add string without URL encoding and it will work here)
NOTE: An attempt made with similar setup configuration from Local windows machine with no success because of certificate issues thrown up .
TROUBLESHOOTING
If the URL encoding is not done properly in ‘url’ string inside the above Perl code, JDBC proxy server will throw below error :
And this in turn leads to very confusing Authentication / SSL / Certificates/ SocketException errors like below :
Though there is various other methods exist to connect via Simba like No Authentication , OAuth 2.0 , LDAP User/Password, Use KeyStore and SSL, I have no success in either approach except the Simple Databricks Auth and Token
Challenges with Perl Language
Popularity :
Below programming index shows that Perl language value diminishes year by year .
Slow community Update. Update on Perl SDK on top of Azure or any Cloud lag by 2-3 years . No Microsoft support using Perl SDK yet .
Usability / Sustainability
Not Developer friendly . High learning curve , complex syntax and programming paradigm than language like Python.
This put immediate risk on sustainability in long term of Perl being put in front on any modern language to talk to Database.
Perl community can’t attract any new developers and beginner users like Python successfully has
Community Support
Lacking day by day , Lack of support in popular developers channel like StackOverflow. I had couple of stackoverflow thread on Perl with very less view and reply from just one person which is not helpful either . So the community is not attractive anymore to any developers
FINAL VERDICT
Use Modern language with Modern Database support for better compatibility , better adoption and availability of easy and fast knowledge powers . This helps scale and make business sustain for years.
The level of trouble I had with Perl I never feel its worth to try Perl ODBC module for DB connectivity.
So if you love pain with your programming platform with zero to no help sure go ahead but get ready to end up with roadblock !































































































You must be logged in to post a comment.